Tutorial: control the size of a Compression model
Tutorial: control the size of a Compression model#
The following section will use the test case Heaviside. This test case is delivered with the NeurEco installation package.
Note
The following operations are available from all the NeurEco interfaces, but in this tutorial only the use of the Python API is presented.
Start by creating an empty directory (HeaviSide Example), in which we will extract the data for this example. The created directory should contain the following files:
x_test.csv
x_train.csv
Once that’s done, we will create import the needed libraries:
from NeurEco import NeurEcoTabular as Tabular
import numpy as np
the next step is to load the training data:
x_train = np.genfromtxt("x_train.csv", delimiter=";", skip_header=True)
At this stage, we will build a compression model without controlling the size of the compressor (this will be our reference point for comparison):
neureco_builder = Tabular.Regressor()
neureco_builder.build(x_train, # the rest of the parameters are optional
write_model_to='./HeavisideModel/Heaviside.ednn',
write_compression_model_to='./HeavisideModelMbed/HeavisideCompressor.ednn',
write_decompression_model_to='./HeavisideModelMbed/HeavisideUncompressor.ednn',
compress_tolerance=0.05,
checkpoint_address='./HeavisideModelMbed/Heaviside.checkpoint',
compress_decompress_size_ratio=1,
minimum_compression_coefficients=3)
Once that’s done, we will create a compression model where the size of the compression block is controlled (In this case, we will assume that the network to be embedded is the compression block). To control the size, we just need to change the parameter compress_decompress_size_ratio. This is a float in the ]0, 1] interval that controls the ratio compression_block_size / decompression_block_size.
neureco_builder.build(x_train, # the rest of the parameters are optional
write_model_to='./HeavisideModel/Heaviside_Mbed.ednn',
write_compression_model_to='./HeavisideModelMbed/HeavisideCompressor_Mbed.ednn',
write_decompression_model_to='./HeavisideModelMbed/HeavisideUncompressor_Mbed.ednn',
compress_tolerance=0.05,
checkpoint_address='./HeavisideModelMbed/Heaviside_Mbed.checkpoint',
compress_decompress_size_ratio=0.3,
minimum_compression_coefficients=3)
Once the two models are created, we will compare their sizes and performances. We will load the testing data, and check the relative l2 error of each compressor on the unseen set of data. After which, we will compare the sizes of the compression block for each compressor.
''' load the testing data '''
x_test = np.genfromtxt("x_test.csv", delimiter=";", skip_header=True)
''' Load the model from the disk'''
compress_model = Tabular.Compressor()
neureco_model = Tabular.Regressor()
# loading and plotting the normal compressor
compress_model.load('./HeavisideModelMbed/Heaviside.ednn')
regular_model_output = compress_model.evaluate(x_test)
regular_error = compress_model.compute_error(regular_model_output, x_test)
print("Error before compressor size control: {0}".format(100 * regular_error))
neureco_model.load('./HeavisideModelMbed/HeavisideCompressor.ednn')
print('Regular Compressor Size: {0}'.format(neureco_model.vec.size))
neureco_model.plot_network()
# loading and plotting the compressor to mbed
compress_model.load('./HeavisideModelMbed/Heaviside_Mbed.ednn')
embedded_model_output = compress_model.evaluate(x_test)
embedded_error = compress_model.compute_error(embedded_model_output, x_test)
print("Error after compressor size control: {0}".format(100 * embedded_error))
neureco_model.load('./HeavisideModelMbed/HeavisideCompressor_Mbed.ednn')
print('Compressor to embed Size: {0}'.format(neureco_model.vec.size))
neureco_model.plot_network()
The previous code will produce the following outputs:
Error before compressor size control: 0.4634996037123345
Regular Compressor Size: 659
Error after compressor size control: 1.3719420032761398
Compressor to embed Size: 63
Notice that we lost a bit of precision, but we reduced the size of the compressor by a factor of 10. If the precision is very important for the use case, we can rebuild the model and select a compress_decompress_size_ratio bigger than the one we chose. The following figure shows us a comparison between the two compressors:
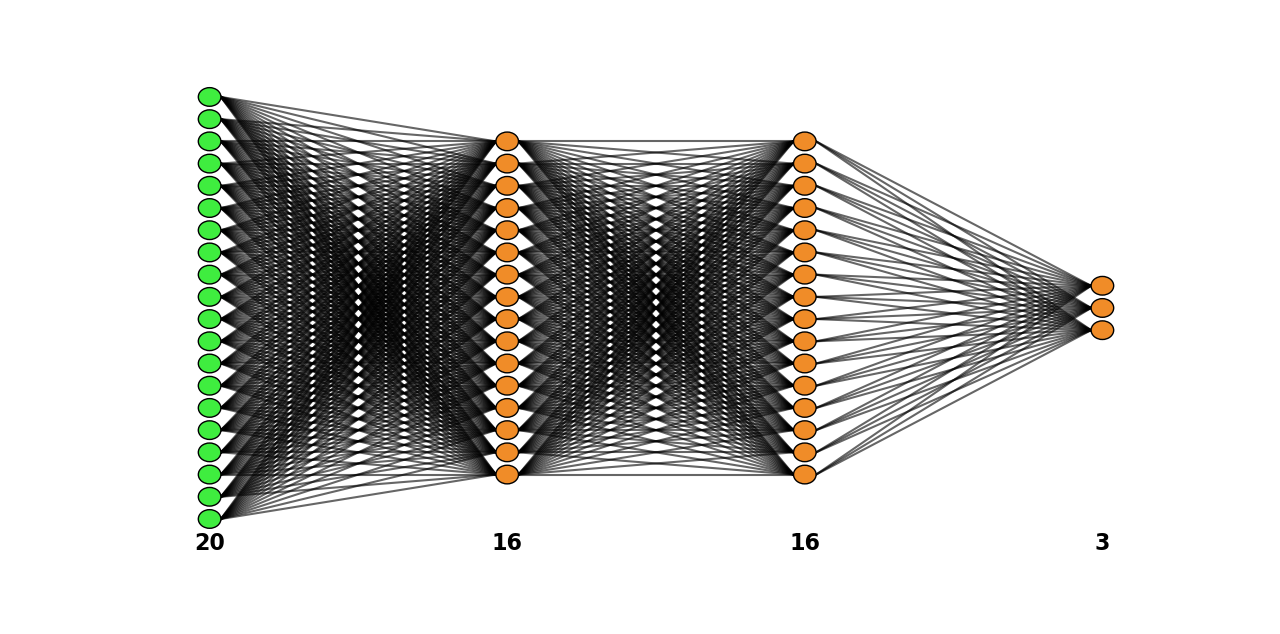
Regular Compressor# |

Embedded Compressor# |