Build NeurEco Compression model with the Python API
Contents
Build NeurEco Compression model with the Python API#
To build a NeurEco Compression model in Python API, import NeurEcoTabular library:
from NeurEco import NeurEcoTabular as Tabular
Initialize a NeurEco object to handle the Compression problem:
model = Tabular.Compressor()
Call method build with the parameters set for the problem under consideration:
model.build(input_data,
validation_input_data=None,
write_model_to="",
write_compression_model_to="",
write_decompression_model_to="",
compress_tolerance=0.01,
valid_percentage=33.33,
use_gpu=False,
inputs_scaling=None,
inputs_shifting=None,
inputs_normalize_per_feature=None,
minimum_compression_coefficients=1,
compress_decompress_size_ratio=1,
start_build_from_model_number=-1,
freeze_structure=False,
initial_beta_reg=0.1,
gpu_id=0,
checkpoint_to_start_build_from="",
checkpoint_address="",
validation_indices=None,
final_learning=True)
- input_data
numpy array, required. Numpy array of training input data. The shape is \((m,\ n)\) where \(m\) is the number of training samples, and \(n\) is the number of input features.
- validation_input_data
numpy array, optional, default = None. Numpy array of validation input data. The shape is \((m,\ n)\) where \(m\) is the number of validation samples, and \(n\) is the number of input features.
- write_model_to
string, optional, default = None. Path where the model will be saved.
- write_compression_model_to
string, optional, default = None. Path where the compression component of the model will be saved.
- write_decompression_model_to
string, optional, default = None. Path where the compression component of the model will be saved.
- compress_tolerance
float, default=0.01, specifies the tolerance of the compressor: the maximum error accepted when performing a compression and a decompression on the validation data.
- validation_indices
numpy array or list, optional, default = None. List of indices of the samples to be used as validation samples, in the training data. If the value is not None, the field valid_percentage will not be used. The lowest accepted index is 1, while the highest is the number of samples.
- valid_percentage
float, optional, default is 33.33%. Percentage of the data that NeurEco will select to use as validation data. The minimum value is 10%, the maximum value is 50%. Ignored when validation_indices or validation_input_data and validation_output_data are provided.
- use_gpu
boolean, optional, default is False. True if GPU will be used for the build.
- inputs_scaling
string, optional, default = ‘auto’. Possible values: ‘max’,’max_centered’, ‘std’, ‘auto’, ‘none’. See Data normalization for Tabular Compression for more details.
- inputs_shifting
string, optional, default = ‘auto’. Possible values: ‘mean’, ‘min_centered’, ‘auto’, ‘none’. See Data normalization for Tabular Compression for more details.
- inputs_normalize_per_feature
bool, optional, default = True. See Data normalization for Tabular Compression for more details.
- minimum_compression_coefficients
int, optional, default=1, specifies the minimum number of nonlinear coefficients when reached NeurEco stops the reducing the number of neurons for the compression layer.
- compress_decompress_size_ratio
float, optional, default is 1.0 specifies the ratio between the sizes of the compression block and the decompression block. This number is always bigger than 0 and smaller or equal to 1. Note that this ratio will be respected in the limit of what NeurEco finds possible.
- start_build_from_model_number
int, default = -1, When resuming a build, specifies which intermediate model in the checkpoint will be used as starting point. when set to -1, NeurEco will choose the last model created as starting point. The model numbers should be in the interval [0, n[ where n is the total number of networks in the checkpoint.
- freeze_structure
bool, default = False, When resuming a build, NeurEco will only change the weights (not the network architecture) if this variable is set to True.
- initial_beta_reg
float, optional, default = 0.1. The initial value of the regularization parameter.
- gpu_id
int, optional, default is 0. id of the GPU card to use when use_gpu=True and multiple cards are available.
- checkpoint_to_start_build_from
default = “”, path to the checkpoint file. . When set, the build starts from the already existing model (for example, while using the same data, when the previous build has stopped for some reason; or by using additional/different data or settings)
- checkpoint_address
string, optional, default = “”. The path where the checkpoint model will be saved. The checkpoint model is used for resuming the build of a model, or for choosing an intermediate network with less topological optimization steps.
- validation_indices
numpy array or list, optional, default = None. List of indices of the samples to be used as validation samples, in the training data. If the value is not None, the field valid_percentage will not be used. The lowest accepted index is 1, while the highest is the number of samples.
- final_learning
boolean, optional, default = True. If set to True, NeurEco includes the validation data into the training data at the very end of the learning process and attempts to improvement the results.
- return
set_status: 0 if ok, other if not
Data normalization for Tabular Compression#
NeurEco can build an extremely effective model just using the data provided by the user, without changing any one of the building parameters. However, the right normalization will make a big difference in the final model performance.
Set inputs_normalize_per_feature to True if trying to fit targets of different natures (temperature and pressure for example) and want to give them equivalent importance.
Set inputs_normalize_per_feature to False if trying to fit quantities of the same kind (a set of temperatures for example) or a field.
If neither of these options suits the problem, normalize the data your own way prior to feeding them to NeurEco (and deactivate output normalization by setting inputs_shifting and inputs_scaling to ‘none’).
A normalization operation for NeurEco is a combination of a \(shift\) and a \(scale\), so that:
Allowed shift methods for NeurEco and their corresponding shifted values are listed in the table below:
Name |
shift value |
|---|---|
none |
\[0\]
|
min |
\[min(x)\]
|
min_centered |
\[-0.5 * (min(x) + max(x))\]
|
mean |
\[mean(x)\]
|
Allowed scale methods for NeurEco Tabular and their corresponding scaled values are listed in the table below:
Name |
scale value |
|---|---|
none |
\[1\]
|
max |
\[max(x)\]
|
max_centered |
\[0.5 * (max(x) - min(x))\]
|
std |
\[std(x)\]
|
Normalization with auto options:
shift is mean and scale is max if the value of mean is far from 0,
shift is none and scale is max if the calculated value of mean is close to 0
If the normalization is performed by feature, and the auto options are chosen, the normalization is performed by group of features. These groups are created based on the values of mean and std.
Particular cases of Build for a Tabular Compression#
Select a model from a checkpoint and improve it#
At each step of the training process, NeurEco records a model into the checkpoint. It is possible to explore the recorded models via the load_model_from_checkpoint function of the python API. Sometimes an intermediate model in the checkpoint can be more relevant for targeted usage than the final model with the optimal precision (for example if it gives a satisfactory precision while being smaller than the final model with the optimal precision and thus can be embedded on the targeted device).
It is possible to export the chosen model as it is from the checkpoint, see Export NeurEco Compression model with the Python API.
The model saved via Export does not benefit from the final learning, which is applied only at the very end of the training.
To apply only the final learning step to the chosen model in the checkpoint:
Prepare the build with exactly the same argument as for the build of the initial model
Change or set the following arguments:
checkpoint_to_start_build_from: path to the checkpoint file of the initial model
start_build_from_model_number: choose the model among saved in the checkpoint
freeze_structure: True
Launch the training
Control the size of the NeurEco Compression model during build#
This figure shows the compression/decompression models generated by a standard NeurEco Tabular compression. The number of links is well balanced between compression and decompression. However, if the user chooses to, that balance could be shifted to create a smaller compressor like shown in the figure below:
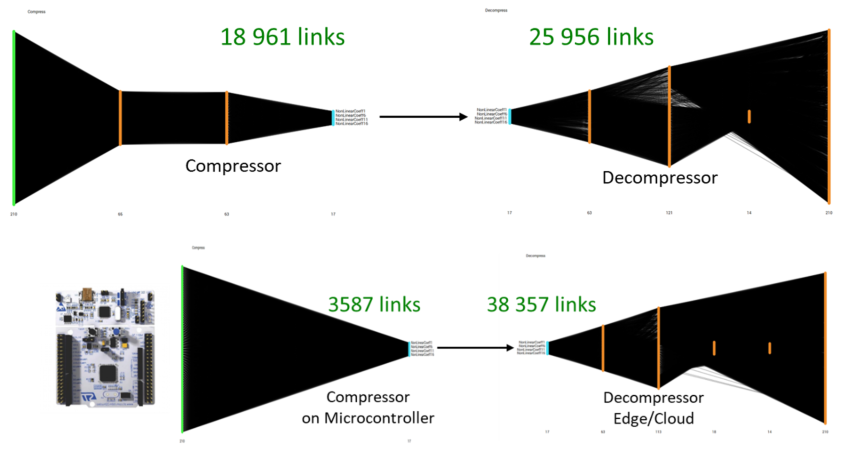
Controlling the size of a compression model#
Note
The size of the compressor running on a microcontroller is reduced, while the size of the decompressor is increased
For a detailed example of the usage of this option, see Tutorial: control the size of a Compression model.